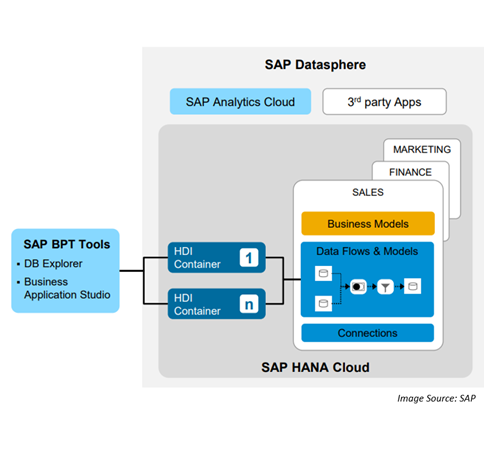
Mastering SAP HANA Cloud Development with HDI Containers and SAP Datasphere
Introduction
It has become apparent that organizations need to store and analyze both their transactional data and their “big data” (unstructured text, video, and so on) together. However, historically, this has been a challenge as there were different types of repositories required depending on which type of data was being processed. Fortunately, solutions to this historic challenge are starting to become a reality. Thus, the integration of enterprise data with big data has become a pivotal strategy for organizations seeking to derive actionable insights. SAP introduced an embedded data lake to SAP Datasphere specifically to address this challenge. This blog delves into the potential of the Embedded Data Lake within SAP Datasphere, addressing common data integration challenges and unlocking the potential for added business value.
The Challenge
Across industries, enterprises grapple with the complexities of integrating SAP transactional data with other types of data. This challenge is rooted in the historical evolution of data repositories. Until relatively recently, there have been different types of repositories required depending on which type of data was being processed. Data Warehouses do a great job as a repository for transactional data. Data Lakes do a good job as a repository for raw, unstructured and semi-structured data. But they stand as separate silos, the implications of this include the following:
Meeting the Challenge: Embedded Data Lake in SAP Datasphere
In a strategic move to address these challenges head-on, SAP unveiled SAP Datasphere, the evolutionary successor to SAP Data Warehouse Cloud, on March 8, 2023. A cornerstone of this innovative offering is the integration of an Embedded Data Lake, providing a seamless and unified data management experience within the SAP ecosystem.
Understanding the Embedded Data Lake
What is a Data Lake?
Before exploring the specifics of the Embedded Data Lake, it’s essential to understand the concept of a data lake. A data lake is a centralized repository that allows organizations to store all their structured and unstructured data at any scale. Unlike traditional data storage systems, data lakes can retain data in its raw format, enabling advanced analytics and deriving valuable insights from diverse data sources.
Embedded Data Lake in SAP Datasphere
An embedded data lake in SAP Datasphere integrates the powerful data lake functionality directly within the SAP environment. This integration provides users with a unified platform where they can store, manage, and analyze their data, leveraging SAP’s advanced analytics tools and applications. By embedding a data lake within SAP Datasphere, organizations can streamline their data management processes and unlock new possibilities for data-driven decision-making.
It has become apparent that organizations need to store and analyze both their transactional data and their “big data” (unstructured text, video, and so on) together. However, historically, this has been a challenge as there were different types of repositories required depending on which type of data was being processed. Fortunately, solutions to this historic challenge are starting to become a reality. Thus, the integration of enterprise data with big data has become a pivotal strategy for organizations seeking to derive actionable insights. SAP introduced an embedded data lake to SAP Datasphere specifically to address this challenge. This blog delves into the potential of the Embedded Data Lake within SAP Datasphere, addressing common data integration challenges and unlocking the potential for added business value.
The Challenge
Across industries, enterprises grapple with the complexities of integrating SAP transactional data with other types of data. This challenge is rooted in the historical evolution of data repositories. Until relatively recently, there have been different types of repositories required depending on which type of data was being processed. Data Warehouses do a great job as a repository for transactional data. Data Lakes do a good job as a repository for raw, unstructured and semi-structured data. But they stand as separate silos, the implications of this include the following:
- Complexity of Data Analysis: It is a challenge to manage, integrate, and analyze data across multiple repositories. The data is not in one unified environment which can be challenging for business users to navigate creating extra overhead and inefficiencies.
- Cost Implications: With multiple repositories, organizations face additional expenditures on software, hardware, licensing, and appropriately skilled resources.
- Operational Overheads: Solutions for items such as data tiering and archiving need to be designed for each repository, creating additional operational overhead.
Meeting the Challenge: Embedded Data Lake in SAP Datasphere
In a strategic move to address these challenges head-on, SAP unveiled SAP Datasphere, the evolutionary successor to SAP Data Warehouse Cloud, on March 8, 2023. A cornerstone of this innovative offering is the integration of an Embedded Data Lake, providing a seamless and unified data management experience within the SAP ecosystem.
Understanding the Embedded Data Lake
What is a Data Lake?
Before exploring the specifics of the Embedded Data Lake, it’s essential to understand the concept of a data lake. A data lake is a centralized repository that allows organizations to store all their structured and unstructured data at any scale. Unlike traditional data storage systems, data lakes can retain data in its raw format, enabling advanced analytics and deriving valuable insights from diverse data sources.
Embedded Data Lake in SAP Datasphere
An embedded data lake in SAP Datasphere integrates the powerful data lake functionality directly within the SAP environment. This integration provides users with a unified platform where they can store, manage, and analyze their data, leveraging SAP’s advanced analytics tools and applications. By embedding a data lake within SAP Datasphere, organizations can streamline their data management processes and unlock new possibilities for data-driven decision-making.
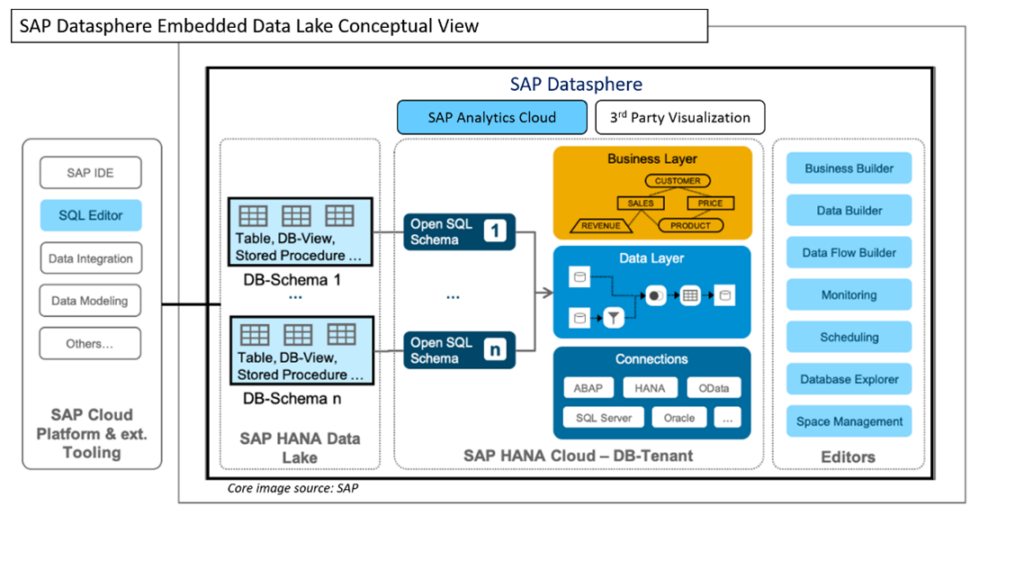
Benefits of Embedded Data Lake in SAP Datasphere
Unified Data Management
The Embedded Data Lake facilitates seamless integration of data within a single platform, streamlining data management processes and reducing operational complexity. The centralized nature of the data lake ensures that all relevant data is readily available, empowering users to make informed choices based on the most up-to-date information.
Scalability and Cost Efficiency
By leveraging the cost-effective data storage options within SAP Datasphere, and eliminating the costs of multiple repository solutions, organizations can optimize their data management costs. By eliminating the need for separate data integration solutions and infrastructure, the Embedded Data Lake drives cost efficiencies and maximizes ROI for businesses.
Data Tiering Scenarios: Cold-to-Hot and Hot-to-Cold
Effective data management often requires balancing performance and cost, which is where data tiering comes into play. The Embedded Data Lake in SAP Datasphere supports two data tiering scenarios to optimize your data storage strategy.
Real-Time Analytics
With SAP Datasphere’s real-time processing capabilities, organizations can derive actionable insights from data in real-time, enabling agile decision-making.
In Conclusion – A Point of View
The Embedded Data Lake in SAP Datasphere represents a paradigm shift. By leveraging the full power SAP Datasphere, it paves the way for a future where data-driven decision-making is not just a possibility but a reality. As we look towards the future, the Embedded Data Lake stands poised to revolutionize the way we harness the power of data, ushering in a new era of innovation and growth. Feel free to reach out to us with questions or to schedule a free live demonstration of the SAP Datasphere embedded data lake.
Unified Data Management
The Embedded Data Lake facilitates seamless integration of data within a single platform, streamlining data management processes and reducing operational complexity. The centralized nature of the data lake ensures that all relevant data is readily available, empowering users to make informed choices based on the most up-to-date information.
Scalability and Cost Efficiency
By leveraging the cost-effective data storage options within SAP Datasphere, and eliminating the costs of multiple repository solutions, organizations can optimize their data management costs. By eliminating the need for separate data integration solutions and infrastructure, the Embedded Data Lake drives cost efficiencies and maximizes ROI for businesses.
Data Tiering Scenarios: Cold-to-Hot and Hot-to-Cold
Effective data management often requires balancing performance and cost, which is where data tiering comes into play. The Embedded Data Lake in SAP Datasphere supports two data tiering scenarios to optimize your data storage strategy.
- Cold-to-Hot: In a Cold-to-Hot tiering scenario, data that is initially stored in a cold tier (less frequently accessed and lower cost) is moved to a hot tier (frequently accessed and higher cost) as it becomes more relevant for real-time analysis. This ensures that critical data is readily available when needed, without incurring high storage costs for less frequently accessed data.
- Hot-to-Cold: Conversely, in a Hot-to-Cold tiering scenario, data that starts in a hot tier (frequently accessed) is moved to a cold tier (less frequently accessed) as its relevance decreases over time. This helps manage storage costs by keeping only the most relevant data in the more expensive, high-performance storage tier.
Real-Time Analytics
With SAP Datasphere’s real-time processing capabilities, organizations can derive actionable insights from data in real-time, enabling agile decision-making.
In Conclusion – A Point of View
The Embedded Data Lake in SAP Datasphere represents a paradigm shift. By leveraging the full power SAP Datasphere, it paves the way for a future where data-driven decision-making is not just a possibility but a reality. As we look towards the future, the Embedded Data Lake stands poised to revolutionize the way we harness the power of data, ushering in a new era of innovation and growth. Feel free to reach out to us with questions or to schedule a free live demonstration of the SAP Datasphere embedded data lake.

Please complete the form to access the whitepaper: