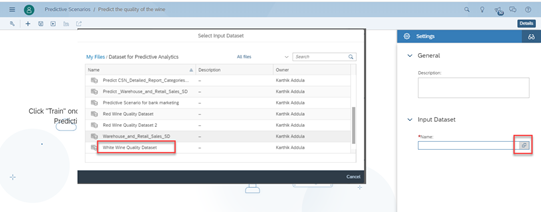
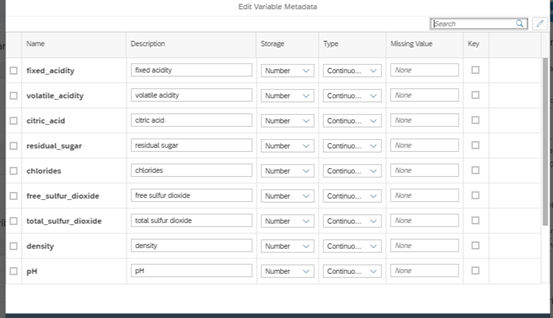
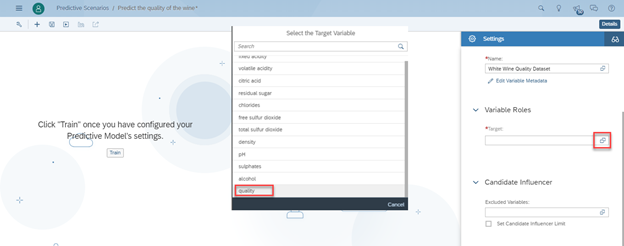
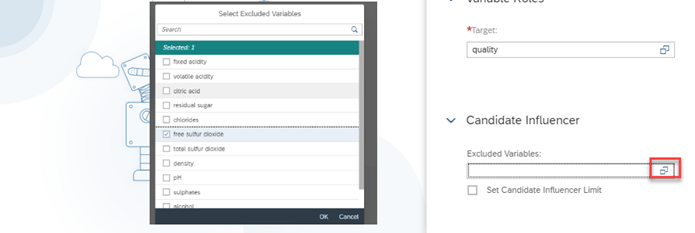
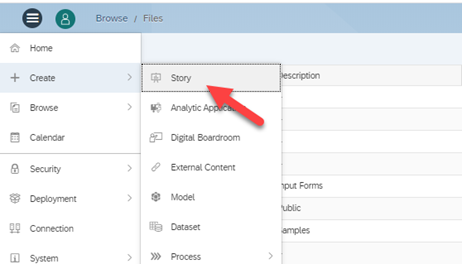
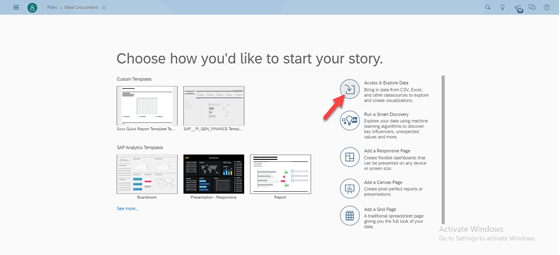
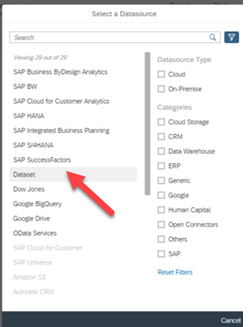
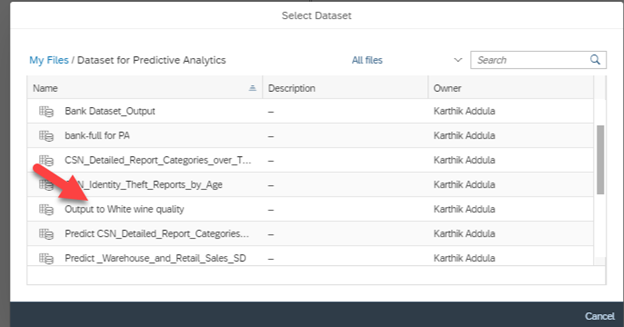
Curious about SAP’s Business Data Cloud announcement and what might it mean to you? We were curious too! We dove in a bit and thought we’d share our initial observations with you.
In case you missed the announcement, Business Data Cloud (BDC) is a new SaaS offering from SAP. It unifies analytics, data management, and AI-driven automation into a single integrated solution. In short it pulls together existing SAP products that are data focused into this new offering. This product leverages Datasphere for comprehensive data warehousing, SAP Analytics Cloud (SAC) for planning and analytics, and integrates Databricks to enhance machine learning (ML) and artificial intelligence (AI) use cases—all while preserving business context.
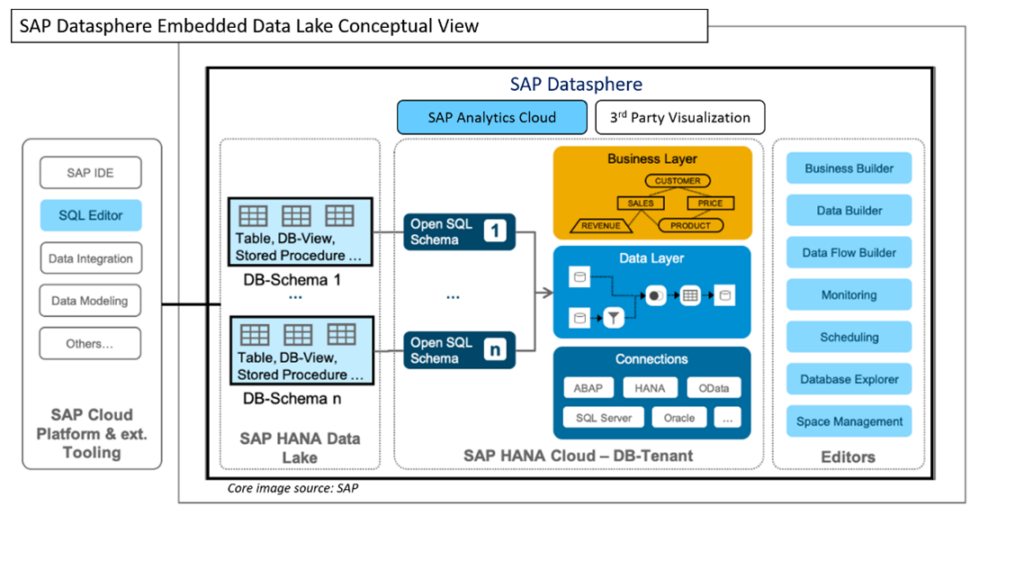
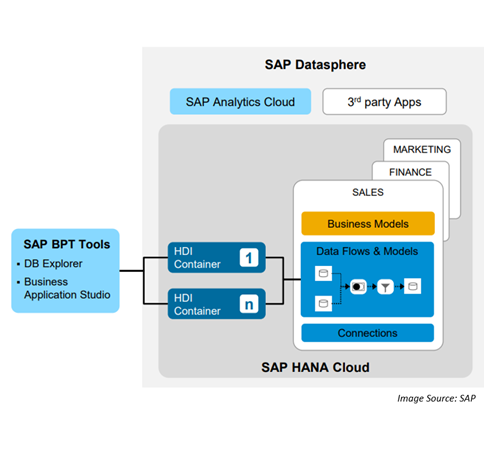
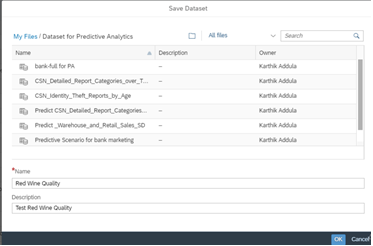
At a high level, the following diagram illustrates the overall high-level conceptual architecture.
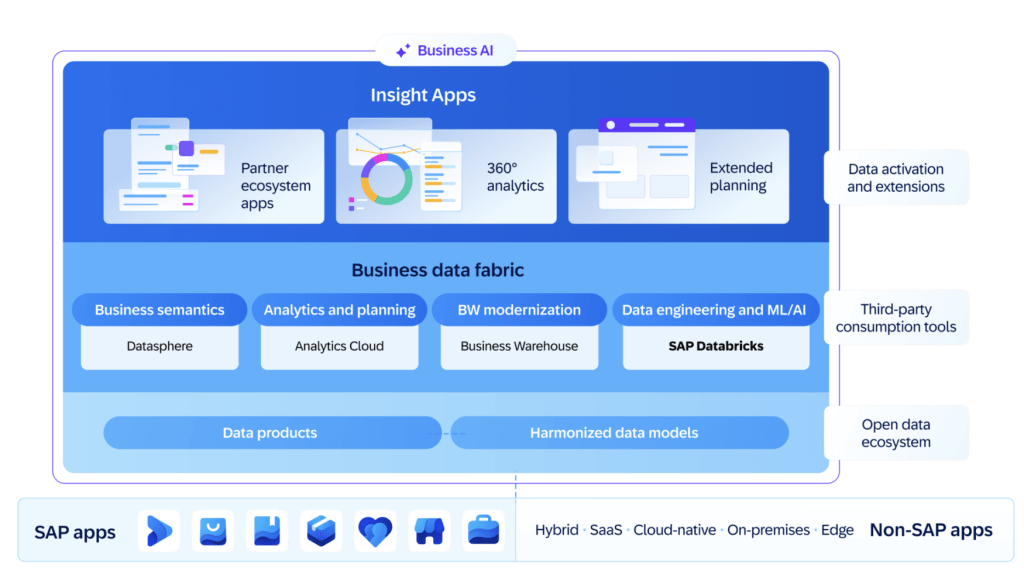
Our initial observations about BDC can be categorized into three buckets: the impact on your data, new opportunities that BDC provides, and the impact to existing Datasphere customers.
Impact on SAP Customers’ Data
One of the biggest challenges SAP customers face today is the need to copy business data into data lakes, a lakehouse, or other cost-effective storage solutions to support ML, AI, and other advanced analytics. This data movement often leads to:
- Loss of business context, making it difficult to interpret data correctly.
- Performance degradation of core SAP applications.
With Business Data Cloud and Databricks integration, customers can now access and process their data directly within the SAP ecosystem without extracting it, ensuring:
- Seamless AI/ML capabilities within SAP without data duplication.
- Optimized performance of SAP applications.
- Preservation of business context, allowing accurate and relevant insights.
New Opportunities
- Customers using SAC for planning can now integrate with Databricks and Data Builder for more advanced analytics.
- Script logics for planning that were previously handled within SAC can now be processed in Data Builder, improving efficiency.
- Predictive modeling and ML-based forecasts on planning data can be executed seamlessly within Databricks while remaining connected to SAP.
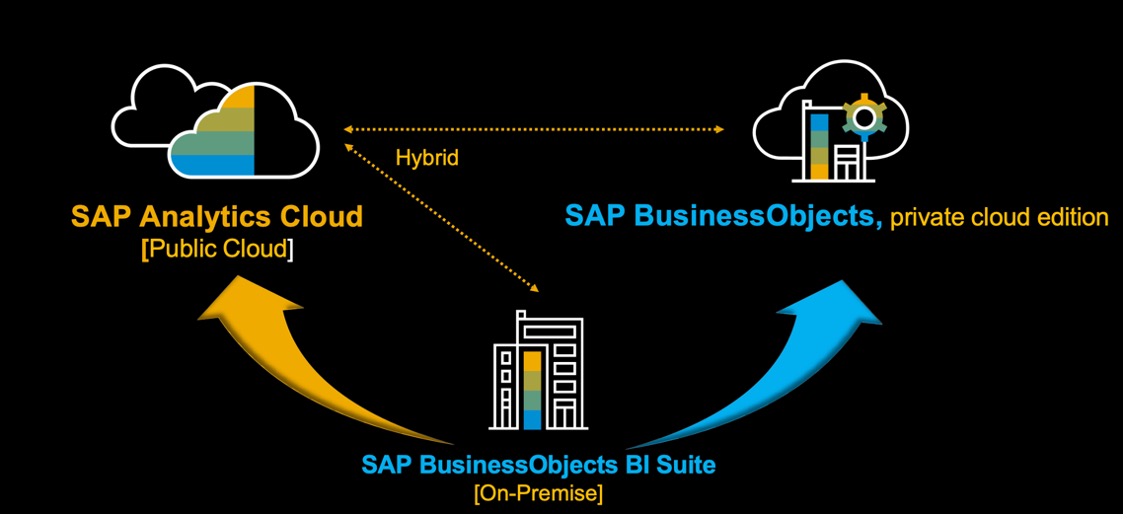
What It Means for Existing Datasphere and SAC Customers
- Datasphere remains foundational and is not being replaced.
- Existing customers can continue using Datasphere and SAC without disruption.
- SAP has committed to a smooth transition plan for customers migrating to Business Data Cloud.
- The migration is expected to be technical in nature rather than a complete overhaul, ensuring that no existing functionalities are lost.
Conclusion
From our initial look, Business Data Cloud holds the promise of eliminating the complexity of data movement, making AI, ML, and analytics more efficient and business context aware. By integrating Datasphere, SAC, and Databricks, SAP has created a robust ecosystem that enables advanced data-driven decision-making while maintaining seamless connectivity and performance.