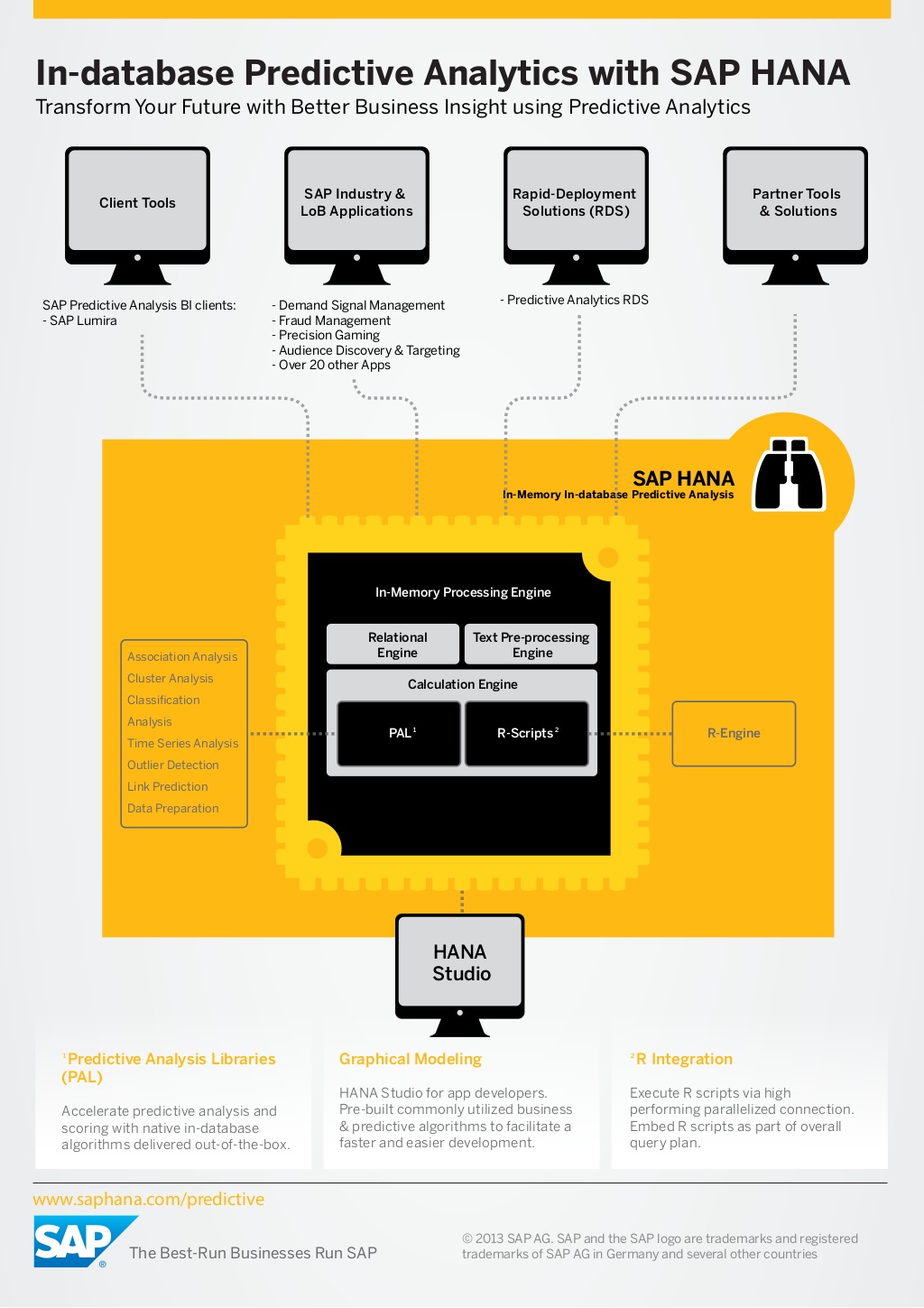
SAP Analytics Cloud is introducing one of the most asked features on Scheduling Stories and Analytical Applications with its latest update 2020.03.
We call it as Schedule Publications. With this, you would be able to Schedule a Story and also an analytical application with recurrence and distribute the same as a PDF over email to a number of different SAC and Non-SAC recipients. And do much more things like, you can even include a customized message in the email per the schedule and attach a link as well to the view of the story in online mode which can be used to check the latest online copy of the story / analytical applications.
Note: Schedule publications would be available only for SAP Analytics cloud Tenants based on the AWS data center (Cloud foundry based).
You can create a single schedule or even a recurring one with a defined frequency like hourly, daily, weekly.
Let’s get started:
At first, Schedule Publications needs to be enabled by your organization SAP Analytics cloud admin on the Tenant level. To do the same, please log in as Admin and go to System -> Administration and enable the Toggle as shown below.
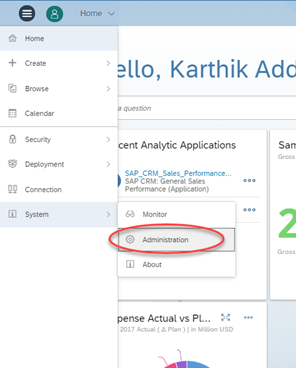
“Allow Schedule Publications” and “Allow Schedule Publication to non-SAC users”
If you want to allow your schedules to be sent over to Non-SAC users as well along with SAC users, Please enable the toggle option as shown below.
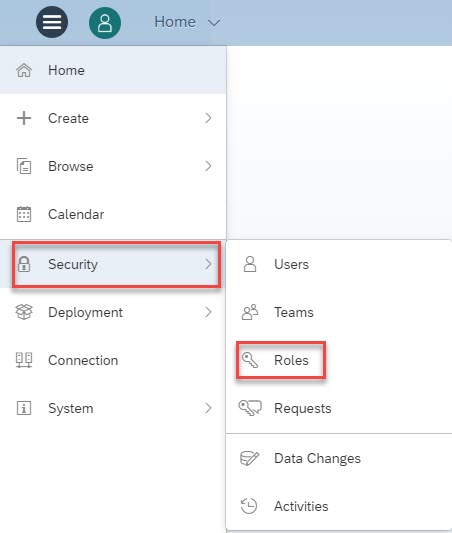
Schedule Publications is not by default enabled to all users in your organization, your admin needs to assign to a template who would have rights for creating schedules. To do the same. under the SAC Tenant application menu. Go under the Security -> Roles and click on any existing role where you would like to add Schedule Publications right.
How to create Schedule Publications?
You can create a schedule IF
- If you are a BI Admin or an Admin. By default, these roles come with the Schedule Publication permission.
- If the Schedule Publication permission has been assigned to a custom role created.
- If you have a Save or Save As permission to a story once the Schedule Publication permission is given.
Once a user has been granted access to create schedules
- Select the Story / Analytical application under the browse files (By using the checkmark) and then choose the option Share -> Schedule Publications as shown below or

- The other way is to open a Story and the again go under share option and select Schedule Publication.

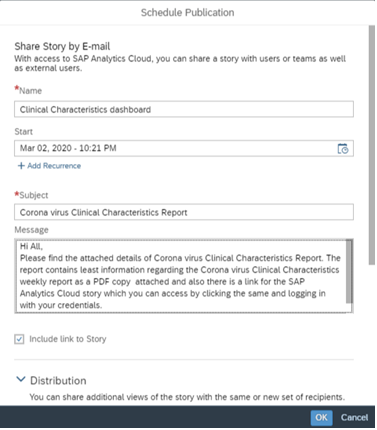
- Once the Schedule Publications Dialog box opens, Input the details as required.
Name: Provide a name for your Schedule
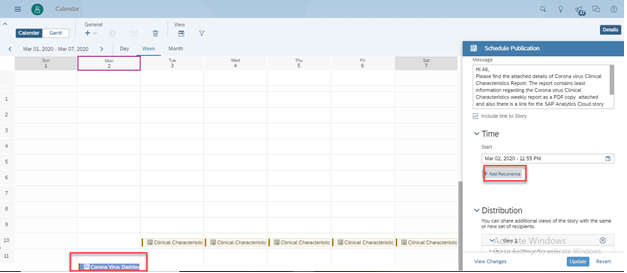
Start: Provide a start date for your schedule with a defined time or you can add recurrence
details as well by selecting the option “Add Recurrence”.
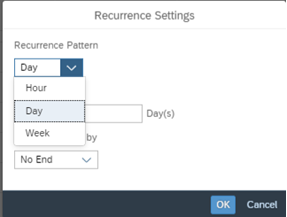
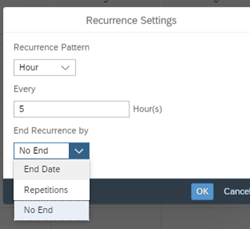
Under Recurrence, you can define the recurrence pattern to be hourly, daily, weekly as different options and also the number of times needs to be repeated including the end of occurrence details.
Topic: This is the subject for the email which would be delivered to the recipients
Message: This is the body of the message for the email which would be sent to the recipients over email.
Include Story Link: If you select this checkmark, then the story/ analytics application link would be sent along with the email. If you happen to personalize the publication by selecting a bookmark to be delivered (Given below), then the personalized bookmark view link would be embedded.
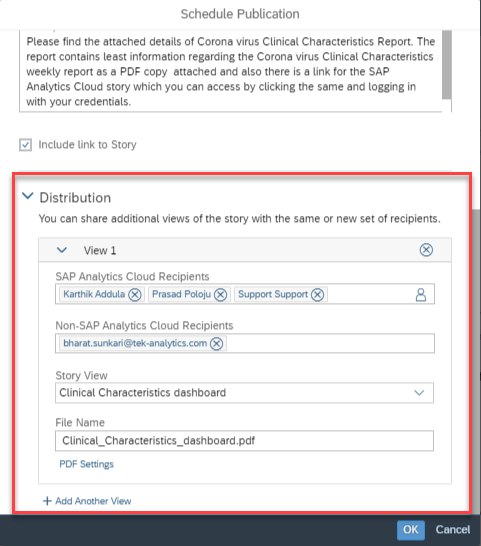
Distribution: Here you can define the view of the story which needs to be delivered to the recipients. You can personalize different users or teams with different views of the same story to be delivered with the help of bookmarks available for stories. If your stories have multiple bookmarks where each of the bookmarks are relevant for different users/teams, you can make use of the same, else create one. The advantage you find with the bookmarks is you can create a unique personalized view by applying different filter options and create views.
Distribution (Continued): You can create one or more than view (as story default view or different bookmarks) which can be delivered to different SAC users/teams. Let’s focus on one view and understand all options. Next to the Down-arrow, Double click “View1” and provide a name for your view. Below screenshot describes to be “Corona virus Clinical Characteristics Report”.
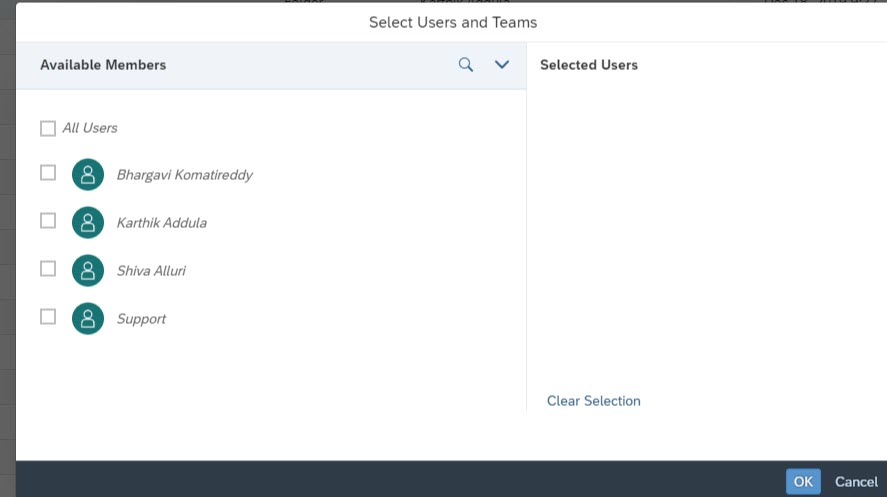
- SAP Analytics Cloud Recipients: Click the person icon and select the different SAC user recipients or teams
- Non-SAP Analytics Cloud Recipients: These are the users who are not a part of SAC user lists or a part of SAC tenant. You can include their email address by manually typing their addresses. Under the default SAC Analytics Cloud licensing, Per View, you can input a maximum of 3 Non-SAC Recipients.
- Story View: Choose the Story/Bookmarks view which you want to deliver to the above recipients. You can choose between Original Story, Global Bookmarks and as well My Bookmarks. the authorization on the story publication would be same as schedule owner and the exact view would be delivered to different recipients.
- File Name: Name of the publication which would be delivered to the recipients
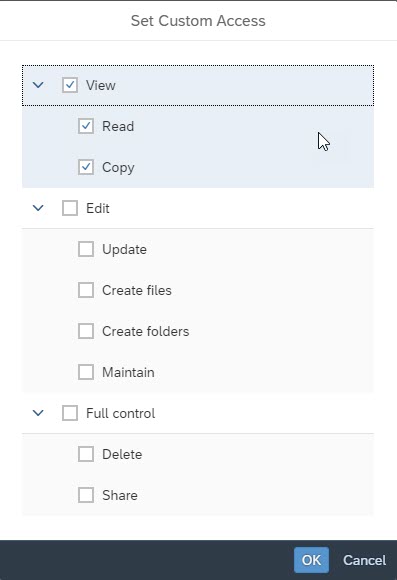
- PDF Settings: You can select this option to define the PDF settings like what all pages you want to deliver, the grid settings for different columns and rows selection, choose to insert appendix which has details on metadata information on the story.
Once you are done with all the details then, Click OK and create your Schedule.
How to view my Schedules created and as well how can I Modify the Schedule?
You can view the Schedule created under the Calendar view. Go to the SAC application menu and select Calendar. You can see the schedule created right there.
If its recurrence schedule, then you would see against multiple different dates /time as defined by the schedule owner.
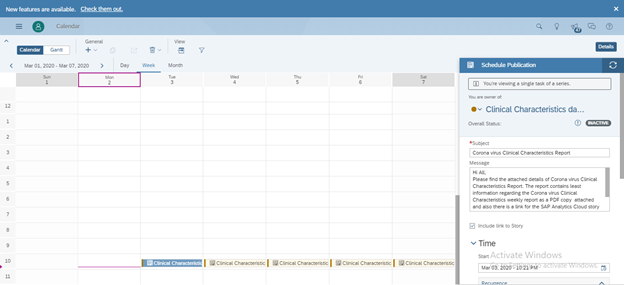
You can as well modify a single recurrence or the entire series occurrence. Select the occurrence from the calendar view and on your right side, a new panel opens where you can modify as shown below.
You can edit the Referrence Setting for Reference Pattern and End Reference by as interested and click on OK and click on Update to save the changes.
As and when the clock ticks it’s time, The Schedule publication picks the job and creates the publications and send it to the different recipients defined as an attachment over email. The maximum mail delivery size allowed per email including attachment is 15MB.
Schedule Publications in itself is a resource intensive tasks which includes the Schedule publications engine on the cloud hosted on SAP Analytics Cloud do a variety of jobs in the background for creating the publications including the email delivery. Out of the box with the standard licensing you would get limited number of schedules.